Sparse matrix
In the subfield of numerical analysis, a sparse matrix is a matrix populated primarily with zeros (Stoer & Bulirsch 2002, p. 619). The term itself was coined by Harry M. Markowitz.
Conceptually, sparsity corresponds to systems which are loosely coupled. Consider a line of balls connected by springs from one to the next; this is a sparse system. By contrast, if the same line of balls had springs connecting each ball to all other balls, the system would be represented by a dense matrix. The concept of sparsity is useful in combinatorics and application areas such as network theory, which have a low density of significant data or connections.
Huge sparse matrices often appear in science or engineering when solving partial differential equations.
When storing and manipulating sparse matrices on a computer, it is beneficial and often necessary to use specialized algorithms and data structures that take advantage of the sparse structure of the matrix. Operations using standard dense matrix structures and algorithms are slow and consume large amounts of memory when applied to large sparse matrices. Sparse data is by nature easily compressed, and this compression almost always results in significantly less computer data storage usage. Indeed, some very large sparse matrices are infeasible to manipulate with the standard dense algorithms.
Contents |
Storing a sparse matrix
The native data structure for a matrix is a two-dimensional array. Each entry in the array represents an element ai,j of the matrix and can be accessed by the two indices i and j. For an m×n matrix, enough memory to store at least (m×n) entries to represent the matrix is needed.
Substantial memory requirement reductions can be realized by storing only the non-zero entries. Depending on the number and distribution of the non-zero entries, different data structures can be used and yield huge savings in memory when compared to a native approach.
Formats can be divided into two groups: (1) those that support efficient modification, and (2) those that support efficient matrix operations. The efficient modification group includes DOK, LIL, and COO and is typically used to construct the matrix. Once the matrix is constructed, it is typically converted to a format, such as CSR or CSC, which is more efficient for matrix operations.
Dictionary of keys (DOK)
DOK represents non-zero values as a dictionary mapping (row, column)-tuples to values. This format is good for incrementally constructing a sparse array, but poor for iterating over non-zero values in sorted order. One typically creates the matrix with this format, then converts to another format for processing
List of lists (LIL)
LIL stores one list per row, where each entry stores a column index and value. Typically, these entries are kept sorted by column index for faster lookup. This is another format which is good for incremental matrix construction. See scipy.sparse.lil_matrix.
Coordinate list (COO)
COO stores a list of (row, column, value) tuples. Ideally, the entries are sorted (by row index, then column index) to improve random access times. This is another format which is good for incremental matrix construction. See scipy.sparse.coo_matrix.
Yale format
The Yale Sparse Matrix Format stores an initial sparse m×n matrix, M, in row form using three one-dimensional arrays. Let NNZ denote the number of nonzero entries of M. The first array is A, which is of length NNZ, and holds all nonzero entries of M in left-to-right top-to-bottom (row-major) order. The second array is IA, which is of length 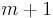 (i.e., one entry per row, plus one).
(i.e., one entry per row, plus one). IA(i) contains the index in A of the first nonzero element of row i. Row i of the original matrix extends from A(IA(i)) to A(IA(i+1)-1), i.e. from the start of one row to the last index before the start of the next. The third array, JA, contains the column index of each element of A, so it also is of length NNZ.
For example, the matrix
[ 1 2 0 0 ] [ 0 3 9 0 ] [ 0 1 4 0 ]
is a three-by-four matrix with six nonzero elements, so
A = [ 1 2 3 9 1 4 ] IA = [ 0 2 4 6 ] JA = [ 0 1 1 2 1 2 ]
In this case the Yale representation contains 16 entries, compared to only 12 in the original matrix. The Yale format saves on memory only when 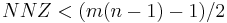 .
.
Compressed sparse row (CSR or CRS)
CSR is effectively identical to the Yale Sparse Matrix format, except that the column array is normally stored ahead of the row index array. I.e. CSR is (val, col_ind, row_ptr), where val is an array of the (left-to-right, then top-to-bottom) non-zero values of the matrix; col_ind is the column indices corresponding to the values; and, row_ptr is the list of value indexes where each row starts. The name is based on the fact that row index information is compressed relative to the COO format. One typically uses another format (LIL, DOK, COO) for construction. This format is efficient for arithmetic operations, row slicing, and matrix-vector products. See scipy.sparse.csr_matrix.
Compressed sparse column (CSC or CCS)
CSC is similar to CSR except that values are read first by column, a row index is stored for each value, and column pointers are stored. I.e. CSC is (val, row_ind, col_ptr), where val is an array of the (top-to-bottom, then left-to-right-bottom) non-zero values of the matrix; row_ind is the row indices corresponding to the values; and, col_ptr is the list of val indexes where each column starts. The name is based on the fact that column index information is compressed relative to the COO format. One typically uses another format (LIL, DOK, COO) for construction. This format is efficient for arithmetic operations, column slicing, and matrix-vector products. See scipy.sparse.csc_matrix. This is the traditional format for specifying a sparse matrix in MATLAB (via the sparse function).
Example
A bitmap image having only 2 colors, with one of them dominant (say a file that stores a handwritten signature) can be encoded as a sparse matrix that contains only row and column numbers for pixels with the non-dominant color.
Band matrix
An important special type of sparse matrices is band matrix, defined as follows. The lower bandwidth of a matrix A is the smallest number p such that the entry aij vanishes whenever i > j + p. Similarly, the upper bandwidth is the smallest p such that aij = 0 whenever i < j − p (Golub & Van Loan 1996, §1.2.1). For example, a tridiagonal matrix has lower bandwidth 1 and upper bandwidth 1. As another example, the following sparse matrix has lower and upper bandwidth both equal to 3. Notice that zeros are represented with dots.
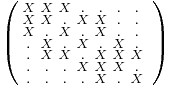
Matrices with reasonably small upper and lower bandwidth are known as band matrices and often lend themselves to simpler algorithms than general sparse matrices; or one can sometimes apply dense matrix algorithms and gain efficiency simply by looping over a reduced number of indices.
By rearranging the rows and columns of a matrix A it may be possible to obtain a matrix A’ with a lower bandwidth. A number of algorithms are designed for bandwidth minimization.
Diagonal matrix
A very efficient structure for an extreme case of band matrices, the diagonal matrix, is to store just the entries in the main diagonal as a one-dimensional array, so a diagonal n×n matrix requires only n entries.
Reducing fill-in
- "Fill-in" redirects here. For the puzzle, see Fill-In (puzzle).
The fill-in of a matrix are those entries which change from an initial zero to a non-zero value during the execution of an algorithm. To reduce the memory requirements and the number of arithmetic operations used during an algorithm it is useful to minimize the fill-in by switching rows and columns in the matrix. The symbolic Cholesky decomposition can be used to calculate the worst possible fill-in before doing the actual Cholesky decomposition.
There are other methods than the Cholesky decomposition in use. Orthogonalization methods (such as QR factorization) are common, for example, when solving problems by least squares methods. While the theoretical fill-in is still the same, in practical terms the "false non-zeros" can be different for different methods. And symbolic versions of those algorithms can be used in the same manner as the symbolic Cholesky to compute worst case fill-in.
Solving sparse matrix equations
Both iterative and direct methods exist for sparse matrix solving.
Iterative methods, such as conjugate gradient method and GMRES utilize fast computations of matrix-vector products 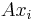 , where matrix
, where matrix  is sparse. The use of preconditioners can significantly accelerate convergence of such iterative methods.
is sparse. The use of preconditioners can significantly accelerate convergence of such iterative methods.
See also
- Matrix representation
- Pareto principle
- Ragged matrix
- Skyline matrix
- Sparse array
- Sparse graph code
- Sparse file
- Harwell-Boeing file format
- Matrix Market exchange formats
References
- Golub, Gene H.; Van Loan, Charles F. (1996). Matrix Computations (3rd ed.). Baltimore: Johns Hopkins. ISBN 978-0-8018-5414-9..
- Stoer, Josef; Bulirsch, Roland (2002). Introduction to Numerical Analysis (3rd ed.). Berlin, New York: Springer-Verlag. ISBN 978-0-387-95452-3..
- Tewarson, Reginald P, Sparse Matrices (Part of the Mathematics in Science & Engineering series), Academic Press Inc., May 1973. (This book, by a professor at the State University of New York at Stony Book, was the first book exclusively dedicated to Sparse Matrices. Graduate courses using this as a textbook were offered at that University in the early 1980s).
- Sparse Matrix Multiplication Package, Randolph E. Bank, Craig C. Douglas [1]
- Pissanetzky, Sergio 1984, "Sparse Matrix Technology", Academic Press
- R. A. Snay. Reducing the profile of sparse symmetric matrices. Bulletin Géodésique, 50:341–352, 1976. Also NOAA Technical Memorandum NOS NGS-4, National Geodetic Survey, Rockville, MD. [2]
Further reading
- Norman E. Gibbs, William G. Poole, Jr. and Paul K. Stockmeyer (1976). "A comparison of several bandwidth and profile reduction algorithms". ACM Transactions on Mathematical Software 2 (4): 322–330. doi:10.1145/355705.355707. http://portal.acm.org/citation.cfm?id=355707.
- John R. Gilbert, Cleve Moler and Robert Schreiber, Schreiber, Robert (1992). "Sparse matrices in MATLAB: Design and Implementation". SIAM Journal on Matrix Analysis and Applications 13 (1): 333–356. doi:10.1137/0613024. http://citeseer.ist.psu.edu/gilbert91sparse.html.
- Sparse Matrix Algorithms Research at the University of Florida, containing the UF sparse matrix collection.
- SMALL project A EU-funded project on sparse models, algorithms and dictionary learning for large-scale data.
External links
- Equations Solver Online
- Oral history interview with Harry M. Markowitz, Charles Babbage Institute, University of Minnesota. Markowitz discusses his development of portfolio theory (for which he received a Nobel Prize in Economics), sparse matrix methods, and his work at the RAND Corporation and elsewhere on simulation software development (including computer language SIMSCRIPT), modeling, and operations research.